Without further ado this post will build upon Volume Shadow Copy Forensics - the Robocopy method Part 1. In part one we looked at using Robocopy to extract data from a single shadow copy at a time. We will now look at a method to extract data from a range of shadow copies in one go. I will also cover some slightly more advanced options.
What are we going to need?
For what follows we will need a Windows 7 box (real or a VM), Encase with the PDE module and some storage space formatted NTFS. Robocopy is pre-installed within Windows 7.
Method
You will already have an Encase image of the drive you wish to investigate. When this is loaded up into an Encase case you need to gather some information in respect to the shadow copies you wish to investigate further. You will need to note the File Creation dates and if you wish to be more precise establish the Shadow Copy IDs stored at File Offset 144 for 16 bytes - bookmark as a GUID in Encase. Next you will have to mount the volume containing the shadow copies as an emulated disk using the Encase PDE module with caching enabled. On my box the mounted volume was allocated the drive letter J. I am using a Windows 7 box - if you are using a Windows 7 VM add the PDE mounted disk to the VM as an additional hard disk. Then on your box or in the VM:
Run a Command Prompt as Administrator and type the command (substituting J for the drive letter allocated to your mounted volume and G:\Shadows with the path of your export directory):
vssadmin list shadows /for=J: > G:\Shadows\list_of_shadow_copies.txt
This will create a text file containing a list of available shadow copies. From the list we can identify a range of shadow copies that we wish to investigate further. We now need to create symbolic links to them using the command:
for /l %i in (22,1,24) do mklink /d c:\Users\Richard\Desktop\Symbolic\SC%i \\?\GLOBALROOT\Device\HarddiskVolumeShadowCopy%i\
note: there is not a space after the ?
This command will create symbolic links for all shadow copy IDs starting at 22 up to 24. Obviously vary the (22,1,24) part to suit - 22 is the start, 1 increments by 1 and 24 is the end value. The symbolic links in this example are being created in a folder C:\Users\Richard\Desktop\Symbolic that I have allocated for this purpose. Many walk throughs, including ones I have prepared, often create the symbolic links at the root of C. Vista and Windows 7 do not like files being stored there so I think it is better practise to create the symbolic links in a user area.
OR
If you do not wish to process a range of shadow copies but need to process more than one or two you can instead use the command:
for %i in (18 20 22) do mklink /d c:\Users\Richard\Desktop\Symbolic\SC%i \\?\GLOBALROOT\Device\HarddiskVolumeShadowCopy%i\
note: there is not a space after the ?
In this example the command process only shadow copy IDs 18, 20 and 22.
Next we will run robocopy over the range of shadow copies we have selected:
for /l %i in (22,1,24) do robocopy c:\Users\Richard\Desktop\Symbolic\SC%i\Users G:\Shadows\SC%i *.jpg *.txt /S /COPY:DAT /XJ /w:0 /r:0 /LOG:G:\Shadows\Robocopy_log_SC%i.txt
OR
for %i in (18 20 22) do robocopy c:\Users\Richard\Desktop\Symbolic\SC%i\Users G:\Shadows\SC%i *.jpg *.txt /S /COPY:DAT /XJ /w:0 /r:0 /LOG:G:\Shadows\Robocopy_log_SC%i.txt
where you are interested in just specific shadow copies.
 This command will create output folders named after each selected shadow copy along with a log of what has been copied. These items are being stored within an export folder prepared for the purpose. In this example I have drilled down to just the Users folder and copied out only jpg and txt files. Please see Part 1 for a detailed explanation of the options used in the command. The output folders can be dragged into Encase as single files. All paths and timestamps have been preserved.
This command will create output folders named after each selected shadow copy along with a log of what has been copied. These items are being stored within an export folder prepared for the purpose. In this example I have drilled down to just the Users folder and copied out only jpg and txt files. Please see Part 1 for a detailed explanation of the options used in the command. The output folders can be dragged into Encase as single files. All paths and timestamps have been preserved.
Network Shares instead of Symbolic Links alternative
In part 1 I touched upon possible permission and copying errors. Troy Larson from Microsoft commented that creating shares instead of symbolic links may overcome some issues. So as an alternative the command:
for /l %i in (22,1,24) do net share SC%i=\\.\HarddiskVolumeShadowCopy%i\
will create network shares entitled SC22, SC23 and SC24 for the shadow copy IDs 22-24. We can now use robocopy to copy data out of these shares:
for /l %i in (22,1,24) do robocopy \\localhost\SC%i\Users G:\Shadows\SC%i *jpg *.txt /S /COPY:DAT /XJ /w:0 /r:0 /LOG:G:\Shadows\Robocopy_log_SC%i.txt
In this example I am accessing the shares on the same box hence localhost but of course you can run this across a network. The resulting data is as before.
Incorrect Function
You may run into what I think is a permission related error - clicking on the symbolic link results in
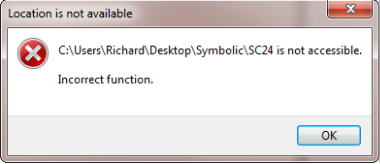
or you see
2010/04/12 15:25:28 ERROR 1 (0x00000001) Accessing Source Directory c:\Users\Richard\Desktop\Symbolic\SC22\Users\Incorrect function.
in your log file.
I have tried myriad ways to overcome this - trying to take ownership of the Shadow Copies using cacls, icacls and everything else but the kitchen sink. However I did eventually find a workaround. In Volume Shadow Copy Forensics.. cannot see the wood for the trees? I discussed imaging shadow copies using George Garner's Forensic Acquisition Utility. This utility appears not to have this issue so the command
for /l %i in (22,1,24) do dd if=\\.\HarddiskVolumeShadowCopy%i of=G:\Shadows\%i.img bs=512 count=1 --localwrt
will image just one sector of each shadow copy in our range. This takes just a few seconds. Then after imaging make your symbolic links or network shares. The Incorrect Function issue is overcome. Don't ask me why.
Cleaning Up
At the conclusion of your investigations you will want to remove the symbolic links or network shares you have created.
To remove the symbolic links
for /l %i in (22,1,24) do rd c:\Users\Richard\Desktop\Symbolic\SC%i
To remove the shares
for /l %i in (22,1,24) do net share SC%i /delete
Dealing with the storage issues
If you want to copy substantial amounts out of a large number of shadow copies you are faced with the problem of where you can store it. In Volume Shadow Copy Forensics.. cannot see the wood for the trees? I observed that there is considerable duplication of files in each shadow copy. I have found that a utility like Duplicate and Same Files Searcher can be useful. This utility can search across your export folders and identify duplicates. You can then opt to retain the first file and then create hard links for all the duplicate files. This utility can also move duplicate files, thus allowing you to focus on just the unique files.
References
Windows 7: Current Events in the World of Windows Forensics Harlen Carvey, Troy Larson
Reliably recovering evidential data from Volume Shadow Copies in Windows Vista and Windows 7 QCC
 I believe there is a middle ground. It is possible to buy 26TB of useable RAID6 storage (32TB raw), a Server and a backup solution for circa £15k. This solution is scalable with further units of 26TB useable storage costing circa £7k each. With a sensible set of operating procedures this type of solution will remain serviceable and fit for purpose for a number of years.
I believe there is a middle ground. It is possible to buy 26TB of useable RAID6 storage (32TB raw), a Server and a backup solution for circa £15k. This solution is scalable with further units of 26TB useable storage costing circa £7k each. With a sensible set of operating procedures this type of solution will remain serviceable and fit for purpose for a number of years. 























