Following on from my post about Safari browser history I want to touch upon Safari cache. My suspect is running Mac OSX 10.5.6 Leopard and Safari 3.2.1. This version stores browser cache in an sqlite3 database ~/Users/User_Name/Library/Caches/com.apple.Safari/Cache.db. Earlier versions of Version 3 and Version 1 and 2 store cache in a different format, and/or a different place. The Episode 3 Shownotes of the Inside the Core Podcast cover this succinctly so I will not repeat it here but FWIW I have cached Safari artefacts in all three forms on the box I have examined. Currently Netanalysis and Encase do not parse the Safari Cache.db file so another method is required.
Safari Cache.db basics
What follows I believe relates to versions 3, 4 and 5 of Safari running in Mac OSX.
The file contains lots of information including the cached data, requesting URL and timestamps. The file is a Sqlite3 database file which has become a popular format to store cached browser data. The cache.db database contains four tables. For the purposes of this post think of each table as a spreadsheet with column headers (field names) and rows beneath representing individual records.
Two tables are of particular interest:
- cfurl_cache_blob_data
- cfurl_cache_response
cfurl_cache_blob_data contains one very notable field and a number of slightly less useful ones. The notable field is receiver_data which is used to store the cached item itself (e.g. cached jpgs, gifs, pngs, html et al ) as a BLOB. A BLOB is a Binary Large OBject. Two other fields request_object and response_object contain information relating to the http request/response cycle also stored as a BLOB which when examined further are in fact xml plists. The entry_ID field is the primary key in this table which will allow us to relate the data in this table to data stored in other tables.
cfurl_cache_response contains two notable fields - request_key and time_stamp. The request_key field is used to contain the URL of the cached item. The time_stamp field is used to store the time (UTC) the item was cached. The entry_ID field is the primary key in this table which will allow us to relate the data in this table to data stored in cfurl_cache_blob_data.
In a nutshell cfurl_cache_blob_data contains the cached item and cfurl_cache_response contains metadata about the cached item.
Safari cache.db examination methods
I would like to share three different methods using SQL queries and a few different tools.
Safari cache.db examination methods - contents quick and dirty
Safari cache.db examination methods - metadata quick and dirty
Safari cache.db examination methods - contents and metadata
Safari cache.db examination methods - contents quick and dirty
Depending on what you wish to achieve there are a number of different methods you can adopt. As regular readers will know I work on many IPOC cases. If all you want to do is quickly review the contents of cache.db (as opposed to the associated meta data) I can not recommend any application more highly than File Juicer. This application runs on the Mac platform (which I know is a gotcha for some) and parses out all cached items into a neat folder structure.
 I drag the File Juicer output folders into Encase as single files and examine the contents further there. File Juicer is not a forensic tool per se but the developer has at least considered the possibility that it may be used as such. If using a Mac is not an option a Windows app SQL Image Viewer may suffice (with the caveat that I have not actually tested this app).
I drag the File Juicer output folders into Encase as single files and examine the contents further there. File Juicer is not a forensic tool per se but the developer has at least considered the possibility that it may be used as such. If using a Mac is not an option a Windows app SQL Image Viewer may suffice (with the caveat that I have not actually tested this app).
Safari cache.db examination methods - metadata quick and dirty
Sometimes overlooked is the fact that most caches contain internet history in the form of urls relating to the cached item. The cfurl_cache_response table contains two fields - request_key and time_stamp containing useful metadata. We can use an SQL query to parse data out of these fields. I use (for variety more than anything else) two different tools (i.e. one or the other) to carry out a quick review of meta data.
Method A using Sqlite3 itself (http://www.sqlite.org/download.html scroll down to the Precompiled Binaries for Windows section)
- extract your cache.db file into a folder
- copy sqlite3.exe into the same folder [to cut down on typing paths etc.]
- launch a command prompt and navigate to your chosen folder
- Type sqlite3 cache.db
- then at the sqlite prompt type .output Cache_metadata.txt [this directs any further output to the file Cache_metadata.txt]
- at sqlite prompt type Select time_stamp, request_key from cfurl_cache_response; [don't forget the semi colon]
- allow a moment or three for the query to complete the output of it's results
- Launch Microsoft Excel and start the Text Import Wizard selecting (step by step) delimited data, set the delimiters to Other | [pipe symbol] and set the Column data format to Text
- Click on Finish then OK and bobs your uncle!
 Click image to view full size
Click image to view full size
Method B using SQLite Database Browser as a viewer in Encase
- from your Encase case send the Cache.db to SQLite Database Browser
- on the Execute SQL tab type in the SQL string field enter Select time_stamp, request_key from cfurl_cache_response
- Review results in the Data returned pane
Or
- from your Encase case send the Cache.db to SQLite Database Browser
- File/Export/Table as CSV file
- Select the cfurl_cache_response Table name
- Open exported CSV in Excel and adjust time_stamp column formatting (a custom date format is required to display seconds)
Safari cache.db examination methods - contents and metadata
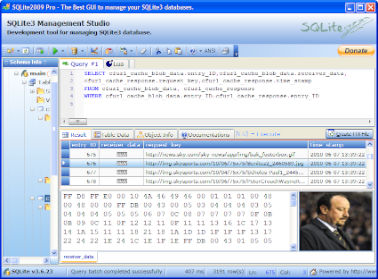
What we need to do here is extract the related data from both tables - in other words be able to view the time stamp, URL and the cached object at the same time. This can be done using SQLite2009 Pro Enterprise Manager. This program has a built in BLOB viewer that will allow you to view the BLOB data in hex and via a image (as in picture) viewer if appropriate.
- Once you have launched the program open your extracted Cache.db file
- In the Query box type (or copy and paste) all in one go
SELECT cfurl_cache_blob_data.entry_ID,cfurl_cache_blob_data.receiver_data, cfurl_cache_response.request_key,cfurl_cache_response.time_stamp
FROM cfurl_cache_blob_data, cfurl_cache_response
WHERE cfurl_cache_blob_data.entry_ID=cfurl_cache_response.entry_ID
- Then key F5 to execute the query
- This will populate the results tab with the results
- To view the cached object BLOB data in the receiver_data field highlight the record of interest with your mouse (but don't click on BLOB in the receiver_data field). This will populate the hex viewer (bottom left) and the BLOB viewer (bottom right).
- To view a full sized version of a cached image click with your mouse on BLOB in the receiver_data field which launches a separate viewing window
 Click on image to view full size
Click on image to view full size
References
SQLite Database File Format
Sindro.me weblog - Extracting data from Apple Safari's cache
http://www.devx.com/dbzone/Article/17403/1954
Inside the Core Episode 3 Show Notes
Define relationships between database tables -Techrepublic











